Culling and batching for GIS applications
Due to the large number entities (road, buildings, landmarks, etc.) that needs to be rendered and loaded on demand in a GIS application a fast way is required for culling but also for loading the map data (i.e. creating the data structures must be cheap and have a low memory footprint).
Also, due to the fact that many objects overlop and have elongated shapes a QuadTree wouldn't produce best results (i.e. overlapping nodes) and have a higher overhead than a Hierarchical RTree, also creating the tree with bulk-loading would be much faster and produce best results.
Consider the following example, for simplicity it's in 2D space:
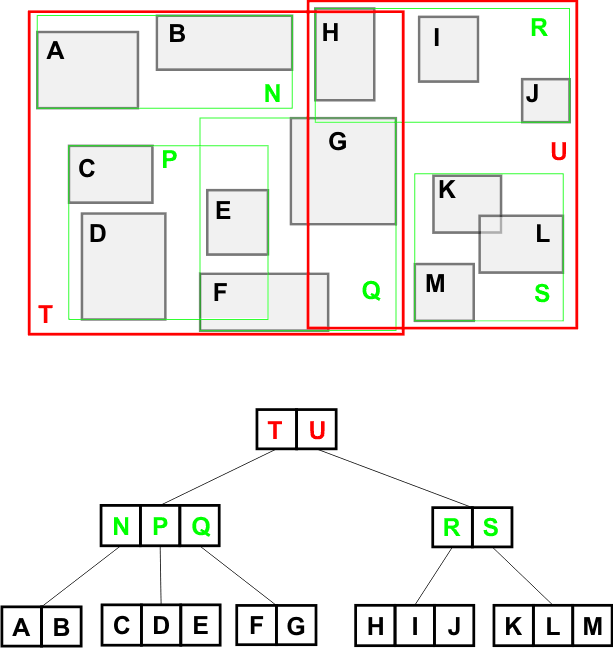
The leaves represent draw calls(eg. game objects) in world coordinates, they can be represented in the tree values by some IDs or indices in some arrays.
Insert the objects in any order, after a leaf traversal(via the leaf iterator) must be done which will give the spatial order of the objects:
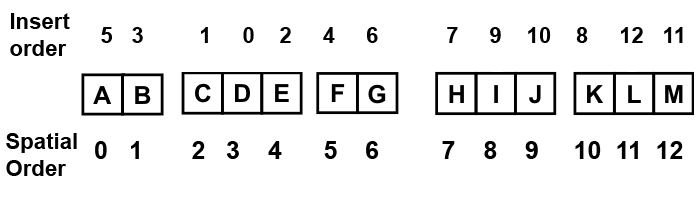
The spatial tree also has a translate method which will be applied to the boxes of all the nodes and leaves.
Afterwards using the spatial order we insert the object's data in a vertex buffer(if applicable, also to an index buffer or more vertex buffers) and save the draw call start and count for the objects:
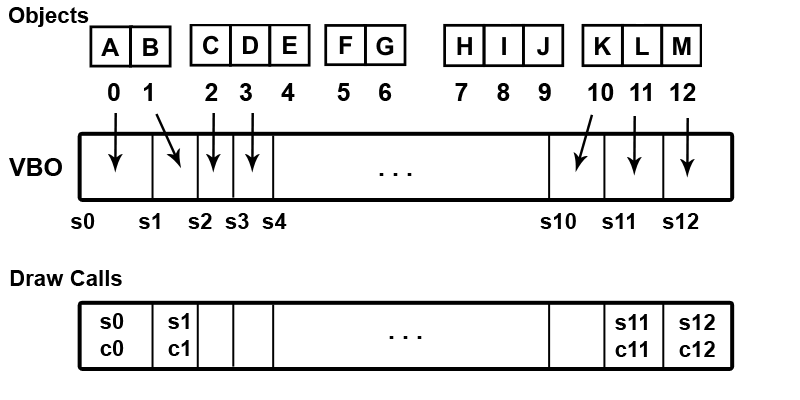
NOTE: It's required that all calls must use the same primitive type.
This way the interleaved data(or indices if using an index buffer) will be spatially ordered.
The final step is to do a depth traversal(via the depth and node iterators) starting from the penultimate level towards the root level(eg. zero). For each depth node access it's children draw calls and append new ones, where the start is the minimum of it's children and count is the sum:
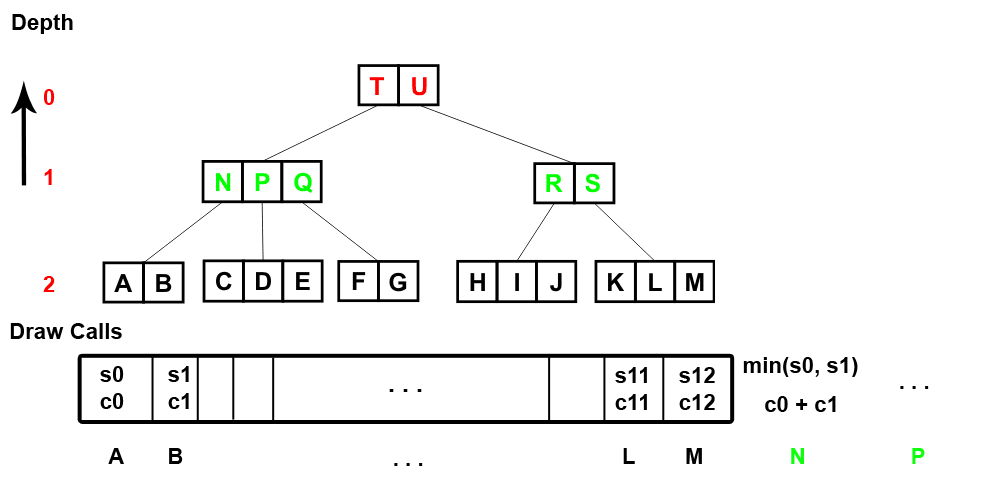
NOTE: The traversal is done in reverse, from the level one downards, in left to right order.
We also set the new values(eg. an ID or address) of depth nodes which will link to the new draw calls.
When using hierachical query the values/objects that are fully contained by the query box will be returned and the other branches pruned.
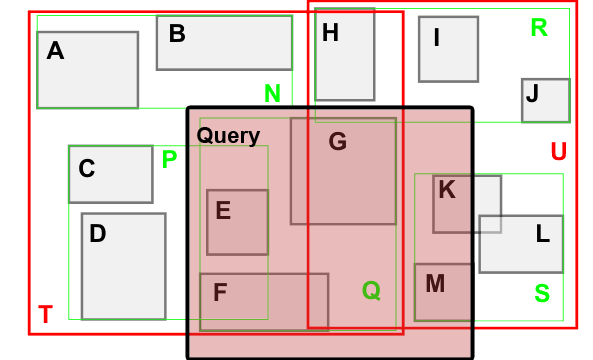
In the above example the query would return the draw calls for: Q(composed of F and G), E, K and M. Note that further optimizations can be done for adjiacent nodes(as they can be merged).
For LOD query the frustum must be splitted based on the number of LOD levels, after you can have a tree per LOD level or you can reuse them between multiple levels. Depending on your LOD scheme and geometry you could batch different objects if their geometry layout and materials are the same (or you can have a lookup ID for their material and save it along the other attributes).
In the following example you can see the culling before (w/o any culling applied to the map tiles) and after, the frustum is split for 3 LOD levels:
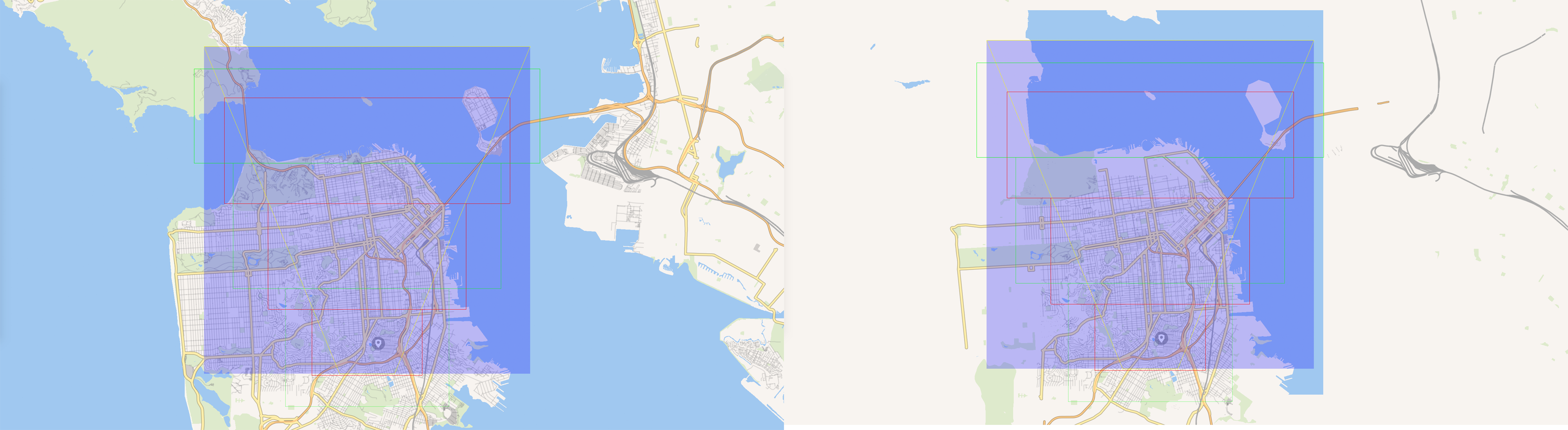
NOTE: There are still some objects that are still rendered despite not being in the frustum, that's due to merging at map data generation and no splitting is performed at runtime.
Finally the geometry buffers must be different between different trees, because of multiple LODs where the geometry is different. If memory footprint is an issue, then one could use more granular queries until a certain tree level (and ignore objects that don't pass a specific thresshold), but would result in more draw calls and overhead.
For more details (benchmarking graphs, usage example, etc) on the RTree implementation you can check it on my github account: link.




