Command buffers for multi-threaded rendering

In this post I will present a C++ lock-free and API agnostic command buffer implementation that can be used for multi-threaded rendering and reducing overhead (state changes, depth sorting) on the main thread. The implementation is based on Stefan Reinalter's blog post1 on multi-thread rendering which I recommend reading as it shows several alternatives and more insight to certain aspects. It also includes a configurable draw key class (via bitfields), implementation of some basic GL commands and supports multiple material passes.
In most cases you will have multiple command buffers for handling specific rendering logic like in the case of a deferred renderer: shadow maps, g-buffer pass, deferred pass and a post-process pass.
Commands will be dispatched into one or more of the command buffers from multiple threads (main thread can also participate as it shouldn't be idle waiting), after which you'll have to wait until all commands are dispatched and it's safe to sort and submit the commands (to the graphics driver) on the main thread:
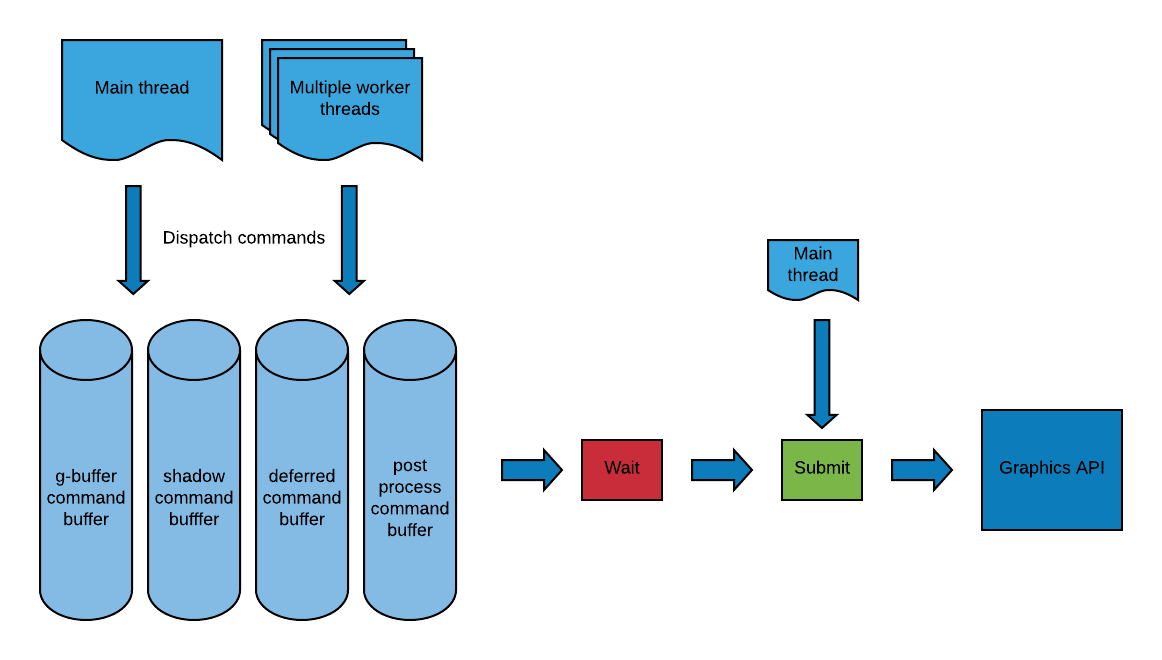
Note that in some cases certain command buffers dont require frequent updates (for example the post processing command buffer) as they only need to be updated when something changes.
Defining a command buffer requires a key type with its decoder class and an optional material binder:
typedef cb::CommandBuffer<cb::DrawKey, cb::DefaultKeyDecoder, Nv::MaterialBinder> GeometryCommandBuffer;
typedef cb::CommandBuffer<uint32_t,cb::DummyKeyDecoder<uint32_t>> DeferredCommandBuffer;
typedef cb::CommandBuffer<uint16_t,cb::DummyKeyDecoder<uint16_t>> PostProcessCommandBuffer;
The command key will be used for sorting the commands, its layout really depends on the use case of the command buffer, for example a shadow command buffer would simply use a 32 bit command representing the depth while for the g-buffer it may be a 64 bit integer that is structured like2:

At the most significant bits there is a viewport ID (for handling multiple viewports), then a view layer (e.g. skybox, world, etc.), translucency type (e.g. opaque, normal, additive, subtractive), a command bit and the rest of the bits will be shared by 3 commands modes: opaque, transparent and custom.
For the transparent and opaque modes, the depth and material ID fields are swapped and a default key decoder handles this:
struct DefaultKeyDecoder
{
/// note Each command key must define a decode function that will be used by the command buffer.
CB_FORCE_INLINE cb::MaterialId operator()(cb::DrawKey key) const
{
return key.material();
}
};
// decode function, get correct material ID as it is swapped
inline cb::MaterialId DrawKey::material() const
{
return isOpaqueMode() ? cb::MaterialId(opaque.materialId, opaque.materialPass)
: cb::MaterialId(transparent.materialId, transparent.materialPass);
}
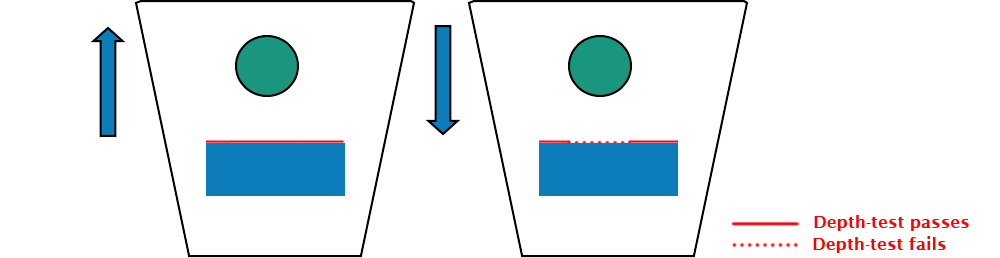
The reason we want to do front to back ordering for the opaque mode is to take advantage of hardware early z-culling, if we're doing a depth pre-pass like most engines do then this can be ignored for opaque objects, this will discard occluded fragments:
The lower bits of the material ID are used by the pass number and can be used to handle multiple material subpasses:
bool nextPass;
do
{
// if true then we have more passes presents in the material
nextPass = m_materialBinder(material);
#if CB_DEBUG_COMMANDS_PRINT
m_materialBinder.debugMsg(material);
CommandPacket::log(packet, *m_logger);
#endif
CommandPacket::dispatch(packet, rc);
++material.pass;
} while (nextPass);
There are multiple ways of creating a command key:
cb::DrawKey key(0);
key.setViewLayer(cb::ViewLayerType::e3D, cb::TranslucencyType::eOpaque);
key.setDepth(depth); // handles swapping based on translucency type
key.setMaterial(materialId);
// using make
key = cb::DrawKey::makeDefault(viewportId, cb::ViewLayerType::e3D);
key = cb::DrawKey::makeCustom(viewportId, cb::ViewLayerType::e3D, priorityNumber);
Finally, custom commands are enabled via the command bit, they can be used for between layers (e.g. view layers, viewports) and can be ordered via a priority (or via command chaining), this way you can change the render target or update vertex buffers before the draw calls.
Creating commands is straightforward, it requires creating a POD struct and defining its dispatch function:
struct DrawArrays {
static const cb::RenderContext::function_t kDispatchFunction;
GLuint vao;
uint32_t base;
uint32_t count;
GLenum primitive;
};
//in cpp
void drawArrays(const void* data, cb::RenderContext*) {
auto& cmd = *reinterpret_cast<const DrawGroundCommand*>(data);
glBindVertexArray(cmd.vao);
glDrawArrays(cmd.primitive, cmd.base, cmd.count);
}
const cb::RenderContext::function_t DrawArrays::kDispatchFunction = &drawArrays;
All commands must be PODs as the default constructor or destructor will not be called due to memory allocation logic, otherwise there will be a compile error, however in cases where you have members that have contiguous memory (or want to handle initialization/allocation manually) but aren't PODs (e.g. a matrix class with constructors) you can hint that the structure is actually a POD via:
struct DrawPointLightCommand
{
static const cb::RenderContext::function_t kDispatchFunction;
// hint that we dont care about ctr/dtr
typedef void pod_hint_tag;
LightingUBO lightingUBO_Data; // non-pod member
For setting up the dispatch function with a member method use makeExecuteFunction that will use the execute member method of the command class:
struct RenderNonInstanced
{
static const cb::RenderContext::function_t kDispatchFunction;
NvModelExtGL* pSourceModel;
GLint positionHandle, normalHandle, texcoordHandle, tangentHandle;
void execute() const
{
pSourceModel->DrawElements(1, positionHandle, normalHandle, texcoordHandle, tangentHandle);
}
};
//in cpp
const cb::RenderContext::function_t RenderNonInstanced::kDispatchFunction = &cb::makeExecuteFunction<RenderNonInstanced>;
Finally note that all the commands must match the alignment of the command buffer allocator. You can match the alignment using the CB_COMMAND_PACKET_ALIGN macro anywhere inside the struct definition or you can disable alignment requirements by setting CB_COMMAND_PACKET_ALIGNED macro to zero (this will result in slightly lower memory consumption of the commands).
In order to reduce state changes, such as binding the same shader or updating uniform buffers with redundant data, a material binder can be used which will handle the logic of setting the active material, note that commands are sorted according to their material id.
For example, a material can be defined as:
struct Material
{
std::string name;
GLuint location = 0;
GLuint ubo = 0;
NvGLSLProgram* shader = nullptr;
};
Afterwards you have to implement the bind operator of the material binder class:
// @note Returns true if there are more passes to bind.
CB_FORCE_INLINE bool operator()(cb::MaterialId material) const
{
if (material.id == 0) // first material is a dummy, nothing to bind
return false;
const Material& mat = materials[material.id];
assert(mat.shader);
if (mat.shader != activeShader)
{
//bind only if different shaders
mat.shader->enable();
activeShader = mat.shader;
}
if (material.id != activeMaterial)
{
// bind material ubo
glBindBufferBase(GL_UNIFORM_BUFFER, mat.location, mat.ubo);
activeMaterial = material.id;
}
// @note you can use material.pass to handle multiple passes for the same material
return false;
}
You can also handle multiple material subpasses by using material.pass. The material binder is optional and by default the command buffer will use a dummy binder, i.e.: cb::DefaultMaterialBinder.
There are multiple ways to dispatch commands and the most common is using addCommand, each time you'll have to use a command key (if possible, it would best to save and reuse it):
//create the command key first
cb::DrawKey key(0);
key.setViewLayer(cb::ViewLayerType::e3D, cb::TranslucencyType::eOpaque);
key.setDepth(depth);
key.setMaterial(materialId);
//then create command which will dispatch it
cmds::DrawArrays& cmd = *commandBuffer.addCommand<cmds::DrawArrays>(key);
cmd.vao = vaoId;
cmd.base = 0;
cmd.count = 4;
cmd.primitive = GL_TRIANGLE_STRIP;
Multiple commands can also be chained together by using appendCommand, that's if they can share the same command key (material, depth, etc.) which will avoid the overhead of material binder:
cb::DrawKey key = cb::DrawKey::makeDefault(viewportId, cb::ViewLayerType::e3D);
//setup key
cmds::DrawArrays* cmd = commandBuffer.addCommand<cmds::DrawArrays>(key);
//fill command data
CB_DEBUG_COMMAND_SET_MSG(cmd, "draw first quad");
//append multiple draw calls
for(int i = 1; i < 10; ++i) {
cmd = commandBuffer.appendCommand<cmds::DrawArrays>(cmd);
//fill command data
...
Commands can also have auxiliary data, like in the case of updating a uniform buffer:
std::vector<float> data;
// create command and allocate auxiliary data
cmds::UpdateUniformCommand& cmd = *commandBuffer.addCommand<cmds::UpdateUniformCommand>(key, sizeof(float) * data.size());
// get the command packet from the command and manually copy the data
CommandPacket* packet = CommandPacket::getCommandPacket<CommandClass>(cmd);
memcpy(packet->auxilaryData, data.data(), sizeof(float) * data.size());
cmd.data = packet->auxilaryData;
cmd.size = sizeof(float) * data.size();
// or you can use the template version which will automatically do the copy
cmds::UpdateUniformCommand& cmd = *commandBuffer.addCommandData<cmds::UpdateUniformCommand>(key, data);
// this will set the data and size members with packet->auxilaryData and size in bytes
struct UpdateUniformCommand
{
static const tn::gpu_dispatch::function_t kDispatchFunction;
// the command must have a data and size as members
const void* data;
uint32_t size;
...
Multiple commands can also share a command (i.e. header packet), for example in a case where you might want to avoid the overhead of copying the command's data:
//create the first the shared command
CommandPacket* headerPacket = buffer.createCommandPacketData<cmds:SetMatrixCommand>(matrices);
//reference/share the command
key = cb::DrawKey::makeDefault(viewportId, cb::ViewLayerType::e3D);
CommandPacket* cmd = buffer.addCommandFrom(key, headerPacket);
//append a new command to the shared one
cmds::DrawArrays* draw = buffer.appendCommand<cmds::DrawArrays>(cmd);
//fill command data
//reference it again
key = cb::DrawKey::makeDefault(otherViewportId, cb::ViewLayerType::e3D);
cmd = buffer.addCommandFrom(key, headerPacket);
draw = buffer.appendCommand<cmds::DrawArrays>(cmd);
//fill command data
...
Before we can submit the commands to the GPU, we first have to sort them (this can also be done on multiple threads if we have too many commands), a custom sort function can also be used:
m_geometryCommands.sort(radixsort<GeometryCommandBuffer::command_t>);
m_deferredCommands.sort();
m_postProcessCommands.sort();
Note that above we used radix sort for the geometry commands, this is due to the way the command key is defined a radix sort will be a little faster in most cases.
Afterwards we simply have to call submit (note that we can pass an optional context data like in the case of D3D):
const bool clearCommands = !m_animPaused; // using recorded commands when paused
// nothing to pass as GL doesn't have any context data
m_geometryCommands.submit(nullptr, clearCommands);
m_deferredCommands.submit(nullptr, clearCommands);
m_postProcessCommands.submit(nullptr, clearCommands);
Due to the fact we copy in the commands all the data required for rendering when dispatching a command, we can reuse the submitted commands and not clear the command buffers. However, to be optimal, we must make sure we don't update any resources (like vertex buffers or textures) in those commands, depending on your use case you could use separate command buffers only for handling resource management.
This can be used to reduce overhead in certain cases, but can also be useful for debugging purposes as you could dump the commands to disk and replay them later. As long you can serialize the commands, in the case of using raw pointers in the commands you have to hard copy the data, and the asset's data (i.e. textures, geometry).
One of the disadvantages of using command buffers compared to a stateful approach is that in some cases it makes debbuging a bit more difficult, this is due to the fact that commands are deferred and submitted on the main thread.
To deal with this tagging commands can be enabled via the CB_DEBUG_TAG_COMMANDS macro and afterwards using:
cb::DrawKey key = cb::DrawKey::makeDefault(viewportId, cb::ViewLayerType::e3D);
cmds::DrawArrays& cmd = *commandBuffer.addCommand<cmds::DrawArrays>(key);
...
// will name tag: 'testFunction : <cpp_line_number> : struct cmds::DrawArrays * __ptr64'
CB_DEBUG_COMMAND_TAG(cmd);
// will name tag: 'testFunction : <cpp_line_number> : struct cmds::DrawArrays * __ptr64 : draw quad'
CB_DEBUG_COMMAND_TAG_MSG(cmd, "draw quad");
// will name tag: 'draw quad'
CB_DEBUG_COMMAND_SET_MSG(cmd, "draw quad");
// can also use a compile time sprint
CB_DEBUG_COMMAND_SET_MSG(cmd, FORMAT_STR("draw quad %d", index));
Enabling command tagging will add packet_debug member inside the CommandPacket:
struct packet_debug
{
static const int kSize = 128;
char tag[kSize];
};
You can also CB_DEBUG_COMMANDS_PRINT macro and if needed define a custom log function (by default it'll use stdout):
//custom log function
int commandLogFunction(const char* fmt, ...)
{
va_list args;
char buffer[1024];
va_start(args, fmt);
vsnprintf(buffer, sizeof buffer, fmt, args);
va_end(args);
NVPlatformLog(buffer);
return 0;
}
//set the log function after
m_geometryCommands.setLogFunction(&commandLogFunction);
In the newer graphics APIs, like Vulkan and D3D12, the concept of command buffer has been introduced at the API level. They can be used with multiple threads (you can have secondary buffers) or be recorded, still this implementation can be useful with new APIs due to its other features such as: sorting via command keys, API agnostic, material binder and multiple passes, it's also less verbose to use.
However certain changes may be required, for example the thread-safe logic (like the lock-free linear allocator) could be an extra template argument only used in cases when it's required to be thread-safe, thus only if you dispatch commands on multiple threads and submit on one.




